class: center, middle, inverse, title-slide .title[ # 12: Multiple Comparisons. ] .subtitle[ ## Linear Models ] .author[ ### <large>Jaye Seawright</large> ] .institute[ ### <small>Northwestern Political Science</small> ] .date[ ### Feb. 16, 2026 ] --- class: center, middle <style type="text/css"> pre { max-height: 400px; overflow-y: auto; } pre[class] { max-height: 200px; } </style> Last time, we saw that researchers test regression results by rejecting `\(H_{0}\)` when the probability associated with it is very low. By convention, there are thresholds at 0.05, 0.01, and 0.001 about which people get emotional. --- Consider the probability of getting a heads on a coin toss. Now consider [this](https://www.youtube.com/watch?v=gOwLEVQGbrM). --- ``` r set.seed(42) # For reproducibility single_experiment <- rbinom(17, size = 1, prob = 0.5) cat("Number of heads in one experiment:", sum(single_experiment), "\n") ``` ``` ## Number of heads in one experiment: 12 ``` ``` r cat("Probability of 17 heads: ", 0.5^17, " (1 in", round(1/0.5^17), ")\n") ``` ``` ## Probability of 17 heads: 7.629395e-06 (1 in 131072 ) ``` --- All right, but what if I flip the coin as many times as I want and count streaks after the fact? ``` r set.seed(123) found_perfect_streak <- FALSE experiments_run <- 0 while(!found_perfect_streak) { experiments_run <- experiments_run + 1 current_experiment <- rbinom(17, size = 1, prob = 0.5) if(sum(current_experiment) == 17) { found_perfect_streak <- TRUE cat("Found 17 heads after", experiments_run, "experiments\n") cat("That's", experiments_run * 17, "total coin flips\n") } } ``` ``` ## Found 17 heads after 57621 experiments ## That's 979557 total coin flips ``` --- ``` r set.seed(42) n_experiments <- 1000 results <- replicate(n_experiments, sum(rbinom(17, 1, 0.5))) max_heads <- max(results) cat("In", n_experiments, "experiments, the maximum heads was:", max_heads, "\n") ``` ``` ## In 1000 experiments, the maximum heads was: 15 ``` ``` r cat("Probability of getting at least", max_heads, "heads by chance:", mean(results >= max_heads), "\n") ``` ``` ## Probability of getting at least 15 heads by chance: 0.002 ``` --- ###The Multiple Comparisons Problem Every significance test we carry out is [a chance to falsely conclude that a relationship is meaningful due to chance](https://xkcd.com/882/). --- If we aren't careful, most times that we pay attention to multiple significance tests related to the same data and the same problem, we are at risk of finding false precision in our results. --- ###Why This Happens Remember that we noted 0.05 as a probability level in significance tests that leads to excitement. This is often written as `\(\alpha = 0.05\)`. If our significance test has been done well, meeting the assumptions we talked about last time, the probability of getting a result of 0.05 or less on a single significance test that corresponds with a population regression slope that is actually 0 is 0.05. So this won't happen very often, and if we have a single result below this level, we can treat it seriously with meaningful confidence. --- However, suppose that we carry out 20 independent significance tests --- including 20 unrelated independent variables in our regression, for example. Now, we can think of each significance test as being like a coin flip in our example above. The chance of finding at least one heads --- at least one value randomly below 0.05 even though the population regression slope is zero --- is going to be much higher than 0.05: ``` r 1 - (0.95)^20 ``` ``` ## [1] 0.6415141 ``` --- <img src="MultipleComparisons_files/figure-html/unnamed-chunk-6-1.png" width="80%" style="display: block; margin: auto;" /> --- We have two main measures of failure when carrying out multiple comparisons: 1. The *family-wide error rate*, which is the probability of incorrectly rejecting even one null hypothesis. 2. The *false discovery rate*, which is the expected proportion of false discoveries (i.e., findings for which we reject the null hypothesis) among all discoveries. --- ###Family-Wide Error Rate `$$\text{FWER} = \text{Pr}(\text{at least one false positive})$$` Intuition: “What’s the chance that any of my ‘significant’ findings is just noise?” Use case: When you need strong control over false positives across all tests (e.g., confirmatory studies, many RCTs). --- ###False-Discovery Rate `$$\text{FDR} = \text{E}(\frac{\text{False Positives}}{\text{All Positives}})$$` --- ###Bonferroni The first and simplest way to correct the family-wide error rate is the Bonferroni correction: just divide `\(\alpha\)` by the number of tests you're carrying out. Suppose our target significance level is `\(\alpha\)` and we're carrying out `\(m\)` total tests. Then the Bonferroni correction is to set our actual target significance level for each individual test at `\(\frac{\alpha}{m}\)` but interpret the results as still just implying a family-wide error rate of not more than `\(\alpha\)`. --- To see why, consider our example of 20 independent tests from earlier. We want `\(\alpha = 0.05\)`, so our Bonferroni-corrected target will be `\(\frac{0.05}{20} = 0.0025\)`. ``` r 1 - (1 - 0.0025)^20 ``` ``` ## [1] 0.04883012 ``` --- If our tests are not independent, the Bonferroni correction will typically be too conservative. --- ### Holm Correction: A Stepwise Improvement Bonferroni is conservative because it treats all tests equally. Holm's step-down procedure is more powerful while still controlling FWER: 1. Order p-values: `\((p_{(1)} \leq p_{(2)} \leq \cdots \leq p_{(m)})\)` 2. Compare `\(p_{(k)}\)` to `\(\frac{\alpha}{m+1-k}\)` 3. Reject all hypotheses up to the first non-rejection --- ``` r # Example: Three tests with p-values 0.004, 0.020, 0.122 p_vals <- c(0.004, 0.020, 0.122) alpha <- 0.05 m <- length(p_vals) # Holm correction manually sorted_p <- sort(p_vals) holm_thresholds <- alpha/(m + 1 - 1:m) cat("Sorted p-values:", sorted_p, "\n") ``` ``` ## Sorted p-values: 0.004 0.02 0.122 ``` ``` r cat("Holm thresholds:", round(holm_thresholds, 3), "\n") ``` ``` ## Holm thresholds: 0.017 0.025 0.05 ``` ``` r cat("Significant under Holm:", sorted_p <= holm_thresholds, "\n") ``` ``` ## Significant under Holm: TRUE TRUE FALSE ``` --- ``` r # Using p.adjust holm_adjusted <- p.adjust(p_vals, method = "holm") cat("Holm-adjusted p-values:", round(holm_adjusted, 3), "\n") ``` ``` ## Holm-adjusted p-values: 0.012 0.04 0.122 ``` --- ### False Discovery Rate: Benjamini-Hochberg While FWER controls "any false positive," FDR controls the *proportion* of false positives among discoveries. Less conservative when many tests are expected to be true positives. --- **Benjamini-Hochberg Procedure:** 1. Order p-values: `\((p_{(1)} \leq \cdots \leq p_{(m)})\)` 2. Find largest `\((k)\)` where `\((p_{(k)} \leq \frac{k}{m}\alpha)\)` 3. Reject all hypotheses 1 through `\((k)\)` --- ``` r # Same three p-values p_vals <- c(0.004, 0.020, 0.122) m <- length(p_vals) # BH thresholds bh_thresholds <- (1:m)/m * alpha cat("BH thresholds:", round(bh_thresholds, 3), "\n") ``` ``` ## BH thresholds: 0.017 0.033 0.05 ``` ``` r cat("Significant under BH:", p_vals <= bh_thresholds, "\n") ``` ``` ## Significant under BH: TRUE TRUE FALSE ``` ``` r # Using p.adjust bh_adjusted <- p.adjust(p_vals, method = "BH") cat("BH-adjusted p-values:", round(bh_adjusted, 3), "\n") ``` ``` ## BH-adjusted p-values: 0.012 0.03 0.122 ``` --- ### Comparing Correction Methods ``` r set.seed(8747) # Simulate 100 tests: 50 null true (mean=0), 50 false (mean=0.5) n_tests <- 100 effects <- c(rep(0, 50), rep(0.5, 50)) p_vals <- 2*pnorm(-abs(rnorm(n_tests, mean = effects))) # Apply corrections corrections <- list( "None" = p_vals, "Bonferroni" = p.adjust(p_vals, "bonferroni"), "Holm" = p.adjust(p_vals, "holm"), "BH" = p.adjust(p_vals, "BH") ) # Count significant at alpha=0.05 sig_counts <- sapply(corrections, function(p) sum(p <= 0.05)) ``` --- ``` r barplot(sig_counts, main = "Significant Tests Under Different Corrections", ylab = "Number Significant (α=0.05)", col = c("#1c5253", "#d3bccc", "#b3dee2", "#f0b7b3"), ylim = c(0, 5)) ``` <!-- --> --- ### When to Use Which Correction? **FWER methods (Bonferroni, Holm):** - Confirmatory research - Small number of tests - Severe consequences of false positives - Clinical trials, policy evaluations **FDR methods (Benjamini-Hochberg):** - Exploratory research - Many tests (e.g., genomics, large-scale surveys) - Willing to accept some false positives to find more true effects --- ### Indexing: Reducing Multiple Outcomes When you measure many related outcomes, combine them into an index: **Mean Effects Index (Kling, Liebman, & Katz, 2004):** 1. Reorient outcomes so higher = better 2. Standardize each outcome by control group: `\((z_{ik} = \frac{y_{ik} - \bar{y}_k^{control}}{SD_k^{control}})\)` 3. Average z-scores for each unit --- **Advantages:** - Increases power when effects are consistent - Handles missing data gracefully - Reduces multiple comparisons problem --- ### Design-Based Approaches **Pre-analysis plans (PAPs):** - Specify hypotheses and analysis plan before seeing data - Define "families" of tests for correction - Distinguish confirmatory vs. exploratory analyses --- **Advantages of PAPs:** - Clarifies multiple comparisons problem - Prevents data dredging - Increases credibility of results --- **Replication:** - The ultimate test: can others reproduce your findings? - Particularly important when dealing with multiple comparisons ---  ---  ---  ---  ---  --- 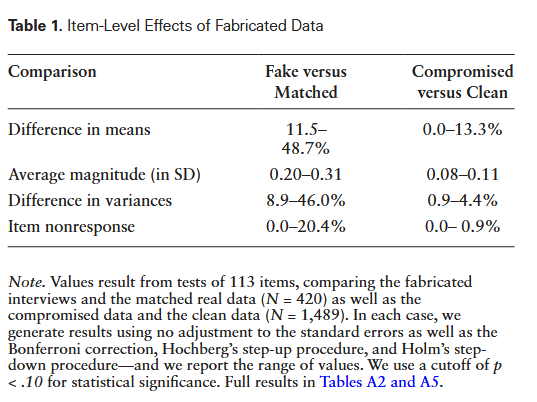 ---