class: center, middle, inverse, title-slide .title[ # 16: Diagnostics. ] .subtitle[ ## Linear Models ] .author[ ### <large>Jaye Seawright</large> ] .institute[ ### <small>Northwestern Political Science</small> ] .date[ ### March 2, 2026 ] --- class: center, middle <style type="text/css"> pre { max-height: 400px; overflow-y: auto; } pre[class] { max-height: 200px; } </style> ### **The Problem** - Regression models make strong assumptions --- ### **The Problem** - Violations can lead to: - **Biased coefficients** - **Invalid inferences** - **Poor predictions** --- # Key Assumptions of Regression ### **1. Validity** Data fit the concepts and populations in the research question - Outcome measures the phenomenon - Model includes relevant predictors - Generalizes to target cases --- # Key Assumptions of Regression ### **2. Representativeness** Sample reflects population (conditional on X) - Selection on X is OK - Selection on Y is problematic - Even with "all" data (e.g., all elections) --- # Key Assumptions of Regression ### **3. Additivity & Linearity** Predictors combine linearly - Some political relationships are nonlinear - Age × voting, income × participation - Nonlinear relationships are fine if we can include them as linear terms --- # Key Assumptions of Regression ### **4. Independence of Errors** No autocorrelation (time/space) --- # Key Assumptions of Regression ### **5. Equal Variance (Homoscedasticity)** Constant prediction uncertainty --- # Key Assumptions of Regression ### **6. Normality of Errors** Least important for estimation --- # Representativeness: Selection Bias ### **The Core Issue** Selection on Y biases coefficients --- ``` r set.seed(123) n <- 1000 pop_data <- data.frame( ideology = rnorm(n, 0, 1), income = rnorm(n, 50000, 15000) ) # Make voting probability depend on ideology and income prob_vote <- plogis(0.5 + 0.3*pop_data$ideology + pop_data$income/100000) pop_data$vote <- rbinom(n, 1, prob_vote) # Selection: only voters in sample sample_data <- pop_data %>% filter(vote == 1) %>% slice_sample(n = 200) cat("Population correlation (ideology, income):", round(cor(pop_data$ideology, pop_data$income), 3), "\n") ``` ``` ## Population correlation (ideology, income): 0.086 ``` ``` r cat("Sample correlation (ideology, income):", round(cor(sample_data$ideology, sample_data$income), 3)) ``` ``` ## Sample correlation (ideology, income): 0.075 ``` --- # Representativeness: Selection Bias ### **Political Science Examples** 1. **Survey non-response** - Political interest → participation → survey response 2. **Media coverage** - Extreme cases get coverage → biased perception --- # Representativeness: Selection Bias ### **Political Science Examples** 3\. **Historical records** - Surviving documents ≠ all documents 4\. **Elite interviews** - Accessible elites ≠ all elites --- # Representativeness: Selection Bias ### **Solutions** - Weighting - Selection models - Multiple data sources --- # Additivity & Linearity: Nonlinear Reality | | | | |:---:|:---:|:---:| |  |  |  | Always check for nonlinearity. Consider transformations or flexible models. --- # Diagnostic Tool 1: Residual Plots ### **What to Plot** ``` r la_electoral <- read.csv("https://raw.githubusercontent.com/jnseawright/ps405/refs/heads/main/Data/laelectoral.csv") # After fitting model fit <- lm(voteswoninc ~ gdpgrowthlag + votesinclag, data = la_electoral) ``` --- ``` r # Base R plot(fit, which = 1) # Residuals vs Fitted ``` <!-- --> --- ``` r la_electoral$countryname[c(70,72,62)] ``` ``` ## [1] "Peru" "Peru" "Guatemala" ``` ``` r la_electoral$electiondate[c(70,72,62)] ``` ``` ## [1] "06/04/06" "06/05/11" "12/28/03" ``` --- ``` r # ggplot2 library(ggplot2) la_electoral$residuals <- resid(fit) la_electoral$fitted <- fitted(fit) residfit.plot <- ggplot(la_electoral, aes(x = fitted, y = residuals)) + geom_point(alpha = 0.6) + geom_hline(yintercept = 0, linetype = "dashed") + geom_smooth(se = FALSE) ``` --- <img src="Diagnostics_files/figure-html/unnamed-chunk-2-1.png" width="80%" style="display: block; margin: auto;" /> --- ### **What to Look For** 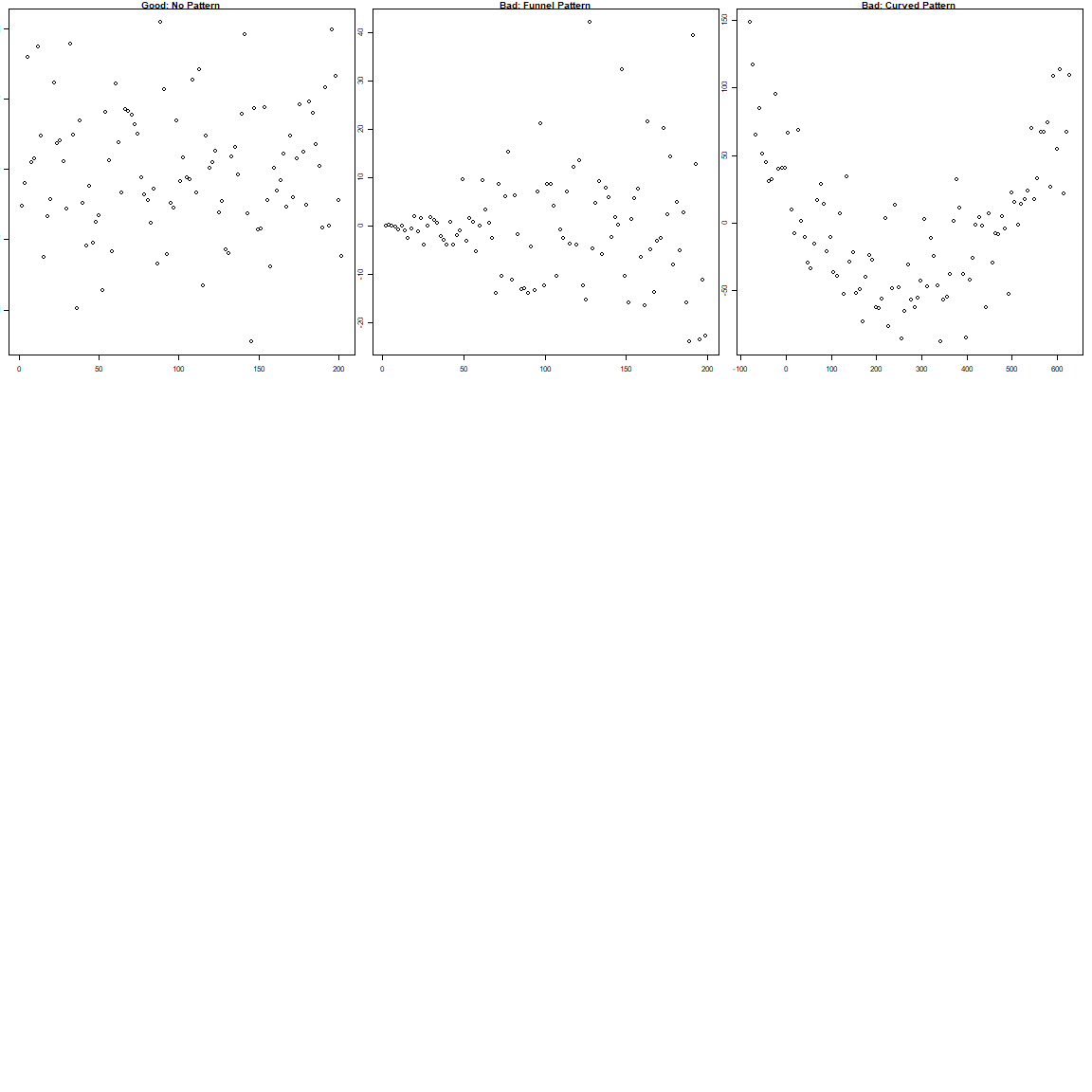<!-- --> --- # Diagnostic Tool 2: Posterior Predictive Checks ### **The Idea** 1. Fit your model 2. Simulate new data from it 3. Compare simulated data to real data 4. If they look different → model problems --- ### **Bayesian Implementation** ``` r # Using rstanarm library(rstanarm) fit_bayes <- stan_glm(voteswoninc ~ gdpgrowthlag + votesinclag, data = la_electoral, family = gaussian(), seed = 123) ``` ``` ## ## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 1). ## Chain 1: ## Chain 1: Gradient evaluation took 0.000108 seconds ## Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 1.08 seconds. ## Chain 1: Adjust your expectations accordingly! ## Chain 1: ## Chain 1: ## Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup) ## Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup) ## Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup) ## Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup) ## Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup) ## Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup) ## Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling) ## Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling) ## Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling) ## Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling) ## Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling) ## Chain 1: Iteration: 2000 / 2000 [100%] (Sampling) ## Chain 1: ## Chain 1: Elapsed Time: 0.101 seconds (Warm-up) ## Chain 1: 0.144 seconds (Sampling) ## Chain 1: 0.245 seconds (Total) ## Chain 1: ## ## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 2). ## Chain 2: ## Chain 2: Gradient evaluation took 3.1e-05 seconds ## Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 0.31 seconds. ## Chain 2: Adjust your expectations accordingly! ## Chain 2: ## Chain 2: ## Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup) ## Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup) ## Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup) ## Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup) ## Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup) ## Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup) ## Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling) ## Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling) ## Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling) ## Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling) ## Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling) ## Chain 2: Iteration: 2000 / 2000 [100%] (Sampling) ## Chain 2: ## Chain 2: Elapsed Time: 0.143 seconds (Warm-up) ## Chain 2: 0.084 seconds (Sampling) ## Chain 2: 0.227 seconds (Total) ## Chain 2: ## ## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 3). ## Chain 3: ## Chain 3: Gradient evaluation took 2.3e-05 seconds ## Chain 3: 1000 transitions using 10 leapfrog steps per transition would take 0.23 seconds. ## Chain 3: Adjust your expectations accordingly! ## Chain 3: ## Chain 3: ## Chain 3: Iteration: 1 / 2000 [ 0%] (Warmup) ## Chain 3: Iteration: 200 / 2000 [ 10%] (Warmup) ## Chain 3: Iteration: 400 / 2000 [ 20%] (Warmup) ## Chain 3: Iteration: 600 / 2000 [ 30%] (Warmup) ## Chain 3: Iteration: 800 / 2000 [ 40%] (Warmup) ## Chain 3: Iteration: 1000 / 2000 [ 50%] (Warmup) ## Chain 3: Iteration: 1001 / 2000 [ 50%] (Sampling) ## Chain 3: Iteration: 1200 / 2000 [ 60%] (Sampling) ## Chain 3: Iteration: 1400 / 2000 [ 70%] (Sampling) ## Chain 3: Iteration: 1600 / 2000 [ 80%] (Sampling) ## Chain 3: Iteration: 1800 / 2000 [ 90%] (Sampling) ## Chain 3: Iteration: 2000 / 2000 [100%] (Sampling) ## Chain 3: ## Chain 3: Elapsed Time: 0.1 seconds (Warm-up) ## Chain 3: 0.125 seconds (Sampling) ## Chain 3: 0.225 seconds (Total) ## Chain 3: ## ## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 4). ## Chain 4: ## Chain 4: Gradient evaluation took 2.2e-05 seconds ## Chain 4: 1000 transitions using 10 leapfrog steps per transition would take 0.22 seconds. ## Chain 4: Adjust your expectations accordingly! ## Chain 4: ## Chain 4: ## Chain 4: Iteration: 1 / 2000 [ 0%] (Warmup) ## Chain 4: Iteration: 200 / 2000 [ 10%] (Warmup) ## Chain 4: Iteration: 400 / 2000 [ 20%] (Warmup) ## Chain 4: Iteration: 600 / 2000 [ 30%] (Warmup) ## Chain 4: Iteration: 800 / 2000 [ 40%] (Warmup) ## Chain 4: Iteration: 1000 / 2000 [ 50%] (Warmup) ## Chain 4: Iteration: 1001 / 2000 [ 50%] (Sampling) ## Chain 4: Iteration: 1200 / 2000 [ 60%] (Sampling) ## Chain 4: Iteration: 1400 / 2000 [ 70%] (Sampling) ## Chain 4: Iteration: 1600 / 2000 [ 80%] (Sampling) ## Chain 4: Iteration: 1800 / 2000 [ 90%] (Sampling) ## Chain 4: Iteration: 2000 / 2000 [100%] (Sampling) ## Chain 4: ## Chain 4: Elapsed Time: 0.108 seconds (Warm-up) ## Chain 4: 0.084 seconds (Sampling) ## Chain 4: 0.192 seconds (Total) ## Chain 4: ``` --- ``` r # Generate posterior predictions y_rep <- posterior_predict(fit_bayes) # Compare distributions bayesplot::ppc_dens_overlay(la_electoral$voteswoninc, y_rep) ``` 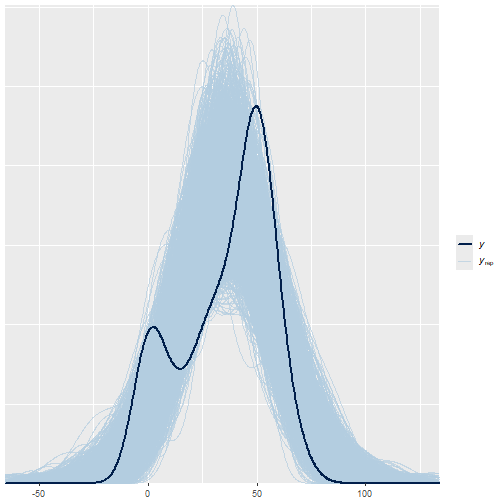<!-- --> --- # Diagnostic Tool 3: Cross-Validation ### **Why CV?** - In-sample fit ≠ out-of-sample performance - Prevents overfitting - Estimates predictive accuracy --- ### **Types of CV** 1. **Leave-One-Out (LOO)** - Each observation left out once - Computationally efficient approximation 2. **K-Fold** (e.g., 10-fold) - Random partitions - More stable with outliers 3. **Time-Series CV** - Train on past, test on future - Critical for political forecasting --- ### **Implementation in R** ``` r library(rstanarm) library(loo) # Fit Bayesian model fit <- stan_glm(vdem_libdem ~ I(log(wdi_gdpcappppcon2017)) + wdi_gerp, data = qogts) ``` ``` ## ## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 1). ## Chain 1: ## Chain 1: Gradient evaluation took 2.7e-05 seconds ## Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 0.27 seconds. ## Chain 1: Adjust your expectations accordingly! ## Chain 1: ## Chain 1: ## Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup) ## Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup) ## Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup) ## Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup) ## Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup) ## Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup) ## Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling) ## Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling) ## Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling) ## Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling) ## Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling) ## Chain 1: Iteration: 2000 / 2000 [100%] (Sampling) ## Chain 1: ## Chain 1: Elapsed Time: 0.079 seconds (Warm-up) ## Chain 1: 0.499 seconds (Sampling) ## Chain 1: 0.578 seconds (Total) ## Chain 1: ## ## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 2). ## Chain 2: ## Chain 2: Gradient evaluation took 2.2e-05 seconds ## Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 0.22 seconds. ## Chain 2: Adjust your expectations accordingly! ## Chain 2: ## Chain 2: ## Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup) ## Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup) ## Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup) ## Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup) ## Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup) ## Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup) ## Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling) ## Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling) ## Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling) ## Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling) ## Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling) ## Chain 2: Iteration: 2000 / 2000 [100%] (Sampling) ## Chain 2: ## Chain 2: Elapsed Time: 0.08 seconds (Warm-up) ## Chain 2: 0.419 seconds (Sampling) ## Chain 2: 0.499 seconds (Total) ## Chain 2: ## ## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 3). ## Chain 3: ## Chain 3: Gradient evaluation took 1.9e-05 seconds ## Chain 3: 1000 transitions using 10 leapfrog steps per transition would take 0.19 seconds. ## Chain 3: Adjust your expectations accordingly! ## Chain 3: ## Chain 3: ## Chain 3: Iteration: 1 / 2000 [ 0%] (Warmup) ## Chain 3: Iteration: 200 / 2000 [ 10%] (Warmup) ## Chain 3: Iteration: 400 / 2000 [ 20%] (Warmup) ## Chain 3: Iteration: 600 / 2000 [ 30%] (Warmup) ## Chain 3: Iteration: 800 / 2000 [ 40%] (Warmup) ## Chain 3: Iteration: 1000 / 2000 [ 50%] (Warmup) ## Chain 3: Iteration: 1001 / 2000 [ 50%] (Sampling) ## Chain 3: Iteration: 1200 / 2000 [ 60%] (Sampling) ## Chain 3: Iteration: 1400 / 2000 [ 70%] (Sampling) ## Chain 3: Iteration: 1600 / 2000 [ 80%] (Sampling) ## Chain 3: Iteration: 1800 / 2000 [ 90%] (Sampling) ## Chain 3: Iteration: 2000 / 2000 [100%] (Sampling) ## Chain 3: ## Chain 3: Elapsed Time: 0.08 seconds (Warm-up) ## Chain 3: 0.436 seconds (Sampling) ## Chain 3: 0.516 seconds (Total) ## Chain 3: ## ## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 4). ## Chain 4: ## Chain 4: Gradient evaluation took 2e-05 seconds ## Chain 4: 1000 transitions using 10 leapfrog steps per transition would take 0.2 seconds. ## Chain 4: Adjust your expectations accordingly! ## Chain 4: ## Chain 4: ## Chain 4: Iteration: 1 / 2000 [ 0%] (Warmup) ## Chain 4: Iteration: 200 / 2000 [ 10%] (Warmup) ## Chain 4: Iteration: 400 / 2000 [ 20%] (Warmup) ## Chain 4: Iteration: 600 / 2000 [ 30%] (Warmup) ## Chain 4: Iteration: 800 / 2000 [ 40%] (Warmup) ## Chain 4: Iteration: 1000 / 2000 [ 50%] (Warmup) ## Chain 4: Iteration: 1001 / 2000 [ 50%] (Sampling) ## Chain 4: Iteration: 1200 / 2000 [ 60%] (Sampling) ## Chain 4: Iteration: 1400 / 2000 [ 70%] (Sampling) ## Chain 4: Iteration: 1600 / 2000 [ 80%] (Sampling) ## Chain 4: Iteration: 1800 / 2000 [ 90%] (Sampling) ## Chain 4: Iteration: 2000 / 2000 [100%] (Sampling) ## Chain 4: ## Chain 4: Elapsed Time: 0.079 seconds (Warm-up) ## Chain 4: 0.444 seconds (Sampling) ## Chain 4: 0.523 seconds (Total) ## Chain 4: ``` ``` r # LOO Cross-Validation loo_result <- loo(fit) print(loo_result) ``` ``` ## ## Computed from 4000 by 4177 log-likelihood matrix. ## ## Estimate SE ## elpd_loo 431.4 43.4 ## p_loo 3.8 0.1 ## looic -862.9 86.8 ## ------ ## MCSE of elpd_loo is 0.0. ## MCSE and ESS estimates assume independent draws (r_eff=1). ## ## All Pareto k estimates are good (k < 0.7). ## See help('pareto-k-diagnostic') for details. ``` ``` r # Compare models fit2 <- stan_glm(vdem_libdem ~ I(log(wdi_gdpcappppcon2017)) + wdi_gerp + as.factor(ht_colonial), data = qogts) ``` ``` ## ## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 1). ## Chain 1: ## Chain 1: Gradient evaluation took 2.8e-05 seconds ## Chain 1: 1000 transitions using 10 leapfrog steps per transition would take 0.28 seconds. ## Chain 1: Adjust your expectations accordingly! ## Chain 1: ## Chain 1: ## Chain 1: Iteration: 1 / 2000 [ 0%] (Warmup) ## Chain 1: Iteration: 200 / 2000 [ 10%] (Warmup) ## Chain 1: Iteration: 400 / 2000 [ 20%] (Warmup) ## Chain 1: Iteration: 600 / 2000 [ 30%] (Warmup) ## Chain 1: Iteration: 800 / 2000 [ 40%] (Warmup) ## Chain 1: Iteration: 1000 / 2000 [ 50%] (Warmup) ## Chain 1: Iteration: 1001 / 2000 [ 50%] (Sampling) ## Chain 1: Iteration: 1200 / 2000 [ 60%] (Sampling) ## Chain 1: Iteration: 1400 / 2000 [ 70%] (Sampling) ## Chain 1: Iteration: 1600 / 2000 [ 80%] (Sampling) ## Chain 1: Iteration: 1800 / 2000 [ 90%] (Sampling) ## Chain 1: Iteration: 2000 / 2000 [100%] (Sampling) ## Chain 1: ## Chain 1: Elapsed Time: 0.116 seconds (Warm-up) ## Chain 1: 0.451 seconds (Sampling) ## Chain 1: 0.567 seconds (Total) ## Chain 1: ## ## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 2). ## Chain 2: ## Chain 2: Gradient evaluation took 2.2e-05 seconds ## Chain 2: 1000 transitions using 10 leapfrog steps per transition would take 0.22 seconds. ## Chain 2: Adjust your expectations accordingly! ## Chain 2: ## Chain 2: ## Chain 2: Iteration: 1 / 2000 [ 0%] (Warmup) ## Chain 2: Iteration: 200 / 2000 [ 10%] (Warmup) ## Chain 2: Iteration: 400 / 2000 [ 20%] (Warmup) ## Chain 2: Iteration: 600 / 2000 [ 30%] (Warmup) ## Chain 2: Iteration: 800 / 2000 [ 40%] (Warmup) ## Chain 2: Iteration: 1000 / 2000 [ 50%] (Warmup) ## Chain 2: Iteration: 1001 / 2000 [ 50%] (Sampling) ## Chain 2: Iteration: 1200 / 2000 [ 60%] (Sampling) ## Chain 2: Iteration: 1400 / 2000 [ 70%] (Sampling) ## Chain 2: Iteration: 1600 / 2000 [ 80%] (Sampling) ## Chain 2: Iteration: 1800 / 2000 [ 90%] (Sampling) ## Chain 2: Iteration: 2000 / 2000 [100%] (Sampling) ## Chain 2: ## Chain 2: Elapsed Time: 0.117 seconds (Warm-up) ## Chain 2: 0.494 seconds (Sampling) ## Chain 2: 0.611 seconds (Total) ## Chain 2: ## ## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 3). ## Chain 3: ## Chain 3: Gradient evaluation took 2e-05 seconds ## Chain 3: 1000 transitions using 10 leapfrog steps per transition would take 0.2 seconds. ## Chain 3: Adjust your expectations accordingly! ## Chain 3: ## Chain 3: ## Chain 3: Iteration: 1 / 2000 [ 0%] (Warmup) ## Chain 3: Iteration: 200 / 2000 [ 10%] (Warmup) ## Chain 3: Iteration: 400 / 2000 [ 20%] (Warmup) ## Chain 3: Iteration: 600 / 2000 [ 30%] (Warmup) ## Chain 3: Iteration: 800 / 2000 [ 40%] (Warmup) ## Chain 3: Iteration: 1000 / 2000 [ 50%] (Warmup) ## Chain 3: Iteration: 1001 / 2000 [ 50%] (Sampling) ## Chain 3: Iteration: 1200 / 2000 [ 60%] (Sampling) ## Chain 3: Iteration: 1400 / 2000 [ 70%] (Sampling) ## Chain 3: Iteration: 1600 / 2000 [ 80%] (Sampling) ## Chain 3: Iteration: 1800 / 2000 [ 90%] (Sampling) ## Chain 3: Iteration: 2000 / 2000 [100%] (Sampling) ## Chain 3: ## Chain 3: Elapsed Time: 0.116 seconds (Warm-up) ## Chain 3: 0.489 seconds (Sampling) ## Chain 3: 0.605 seconds (Total) ## Chain 3: ## ## SAMPLING FOR MODEL 'continuous' NOW (CHAIN 4). ## Chain 4: ## Chain 4: Gradient evaluation took 2.1e-05 seconds ## Chain 4: 1000 transitions using 10 leapfrog steps per transition would take 0.21 seconds. ## Chain 4: Adjust your expectations accordingly! ## Chain 4: ## Chain 4: ## Chain 4: Iteration: 1 / 2000 [ 0%] (Warmup) ## Chain 4: Iteration: 200 / 2000 [ 10%] (Warmup) ## Chain 4: Iteration: 400 / 2000 [ 20%] (Warmup) ## Chain 4: Iteration: 600 / 2000 [ 30%] (Warmup) ## Chain 4: Iteration: 800 / 2000 [ 40%] (Warmup) ## Chain 4: Iteration: 1000 / 2000 [ 50%] (Warmup) ## Chain 4: Iteration: 1001 / 2000 [ 50%] (Sampling) ## Chain 4: Iteration: 1200 / 2000 [ 60%] (Sampling) ## Chain 4: Iteration: 1400 / 2000 [ 70%] (Sampling) ## Chain 4: Iteration: 1600 / 2000 [ 80%] (Sampling) ## Chain 4: Iteration: 1800 / 2000 [ 90%] (Sampling) ## Chain 4: Iteration: 2000 / 2000 [100%] (Sampling) ## Chain 4: ## Chain 4: Elapsed Time: 0.113 seconds (Warm-up) ## Chain 4: 0.486 seconds (Sampling) ## Chain 4: 0.599 seconds (Total) ## Chain 4: ``` ``` r loo2 <- loo(fit2) loo_compare(loo_result, loo2) ``` ``` ## elpd_diff se_diff ## fit2 0.0 0.0 ## fit -215.9 22.6 ``` --- ### **Interpretation** - `elpd_diff`: Difference in expected log predictive density - Rule of thumb: `elpd_diff > 4` suggests meaningful difference --- class: inverse ## Multicollinearity ### Definition - High correlation among predictors. - Not a violation of assumptions, but a data problem that affects precision. ### Consequences - Large standard errors → coefficients may become insignificant even if important. - Coefficients sensitive to small changes in data/model. - Interpretation becomes difficult (partial effects not well estimated). --- ### Detecting Multicollinearity **1. Variance Inflation Factor (VIF)** `$$\text{VIF}_j = \frac{1}{1 - R_j^2}$$` where `\((R_j^2)\)` is from regressing `\((X_j)\)` on all other predictors. - Rule of thumb: VIF > 5–10 indicates problematic collinearity. - Equivalent: tolerance `\((< 0.1)–0.2\)`. --- ``` r # Using mtcars dataset library(car) data(mtcars) fit_mpg <- lm(mpg ~ disp + hp + wt + qsec, data = mtcars) vif(fit_mpg) # from car package ``` ``` ## disp hp wt qsec ## 7.985439 5.166758 6.916942 3.133119 ``` --- ### Detecting Multicollinearity (cont.) **2. Condition Index** (from eigen decomposition of scaled X'X) - Condition index > 30 suggests moderate to strong collinearity. - Available via `collin.diag()` in `perturb` package or manually. **3. Correlation Matrix** (simple pairwise correlations) - High pairwise correlations (> 0.8) are a red flag, but multicollinearity can involve more than two predictors. --- ``` r cor(mtcars[, c("disp", "hp", "wt", "qsec")]) ``` ``` ## disp hp wt qsec ## disp 1.0000000 0.7909486 0.8879799 -0.4336979 ## hp 0.7909486 1.0000000 0.6587479 -0.7082234 ## wt 0.8879799 0.6587479 1.0000000 -0.1747159 ## qsec -0.4336979 -0.7082234 -0.1747159 1.0000000 ``` --- ### Remedies for Multicollinearity - **Do nothing** if only interested in prediction (VIF doesn't affect predictions). - **Drop one of the correlated predictors** (theory-driven). - **Combine variables** (e.g., index, PCA, factor analysis). - **Ridge regression** (penalized estimation) or **LASSO**. - **Collect more data** (often impractical). --- class: inverse ## Autocorrelation (Serial Correlation) ### Definition - Errors are correlated across observations (time series: ε_t correlated with ε_{t-1}; spatial: neighbors correlated). - Violates **independence of errors** assumption. ### Consequences - Standard errors biased (usually downward for positive autocorrelation) → t-statistics inflated → spurious significance. - Coefficients remain unbiased but inefficient. --- ### Detecting Autocorrelation **1. Residual Plot vs. Time/Order** - Look for patterns (runs of positive/negative residuals). --- ``` r # Example using economics dataset (from ggplot2) data(economics) economics$date <- as.Date(economics$date) fit_ue <- lm(unemploy ~ pce + pop, data = economics) economics$resid <- resid(fit_ue) ggplot(economics, aes(x = date, y = resid)) + geom_line() + geom_hline(yintercept = 0, linetype = "dashed") + labs(title = "Residuals over time") ``` 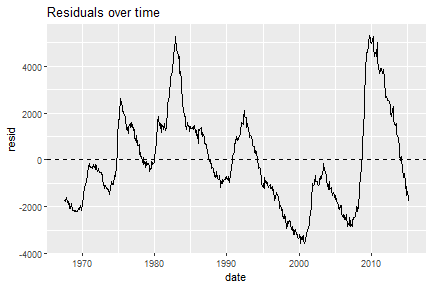<!-- --> --- **2. Durbin–Watson Test** - Tests for AR(1) autocorrelation. - H₀: no autocorrelation (ρ = 0). - Test statistic d ≈ 2(1 - ρ̂). d near 2 → no AR(1); d < 2 → positive autocorrelation; d > 2 → negative. - But only detects first-order autocorrelation. --- ``` r library(lmtest) dwtest(fit_ue) # Durbin-Watson test ``` ``` ## ## Durbin-Watson test ## ## data: fit_ue ## DW = 0.011121, p-value < 2.2e-16 ## alternative hypothesis: true autocorrelation is greater than 0 ``` --- **3. Breusch–Godfrey Test** - More general: tests for higher-order autocorrelation (AR(p) or MA(q)). - Regress residuals on lagged residuals and original predictors. - H₀: no autocorrelation up to order p. --- ``` r bgtest(fit_ue, order = 2) # test for AR(2) autocorrelation ``` ``` ## ## Breusch-Godfrey test for serial correlation of order up to 2 ## ## data: fit_ue ## LM test = 567.07, df = 2, p-value < 2.2e-16 ``` **4. ACF/PACF Plots of Residuals** ``` r acf(resid(fit_ue), main = "ACF of Residuals") ``` 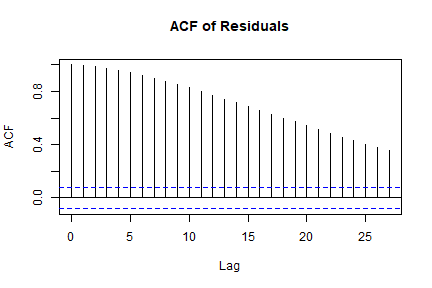<!-- --> ``` r pacf(resid(fit_ue), main = "PACF of Residuals") ``` <!-- --> --- ### Remedies for Autocorrelation - **Include lagged dependent variable** (but careful with interpretation). - **Use autoregressive error models** (e.g., `gls` with AR structure in `nlme`). - **Newey-West standard errors** (HAC: heteroskedasticity and autocorrelation consistent). - **First-differencing** for strong unit-root type persistence. - **Panel data**: use fixed effects with clustered standard errors. --- class: inverse ## Nonlinearity ### Definition - The true relationship between Y and X is not linear, but we fit a linear model. - Violates **linearity** and **additivity** assumptions. ### Consequences - Biased coefficients and poor predictions. - Misspecified functional form. --- ### Detecting Nonlinearity **1. Residuals vs. Fitted Plot** - Already covered: curved pattern suggests nonlinearity. **2. Partial Residual Plots (Component + Residual)** - Show relationship between Y and one X after accounting for other predictors. - Smoother helps visualize nonlinearity. --- ``` r fit_mpg2 <- lm(mpg ~ disp + hp + wt, data = mtcars) crPlots(fit_mpg2, terms = ~ disp) # partial residual for disp ``` <!-- --> --- **3. Ramsey's RESET Test (Regression Specification Error Test)** - Adds powers of fitted values to the model and tests if they improve fit. - H₀: model is correctly specified (no nonlinearity/omitted variables). --- ``` r resettest(fit_mpg2, power = 2:3, type = "fitted") ``` ``` ## ## RESET test ## ## data: fit_mpg2 ## RESET = 7.2382, df1 = 2, df2 = 26, p-value = 0.00317 ``` ``` r # significant p-value -> evidence of misspecification ``` **4. Visualizing with Scatterplots + Smoothers** ``` r ggplot(mtcars, aes(x = wt, y = mpg)) + geom_point() + geom_smooth(method = "loess", se = FALSE) + geom_smooth(method = "lm", color = "red", se = FALSE) ``` <!-- --> --- ### Remedies for Nonlinearity - **Transform predictors** (log, square root, Box–Cox). - **Add polynomial terms** (e.g., X², X³) – beware of overfitting. - **Use splines** (e.g., `bs()` or `ns()` in `splines` package). - **Generalized additive models (GAMs)** for flexible smooth terms. - **Theory-driven nonlinear specifications** (e.g., diminishing returns). --- class: inverse ## Normality of Errors ### Importance - **Not required for unbiasedness or consistency** of OLS coefficients. - Required for **exact finite-sample inference** (t- and F-tests) – but with large N, CLT kicks in. - Violations can affect efficiency and prediction intervals. ### When to worry - Small samples (n < 30–50). - Extreme skew or heavy tails (outliers) that influence standard errors. --- ### Detecting Non‑Normality **1. Q–Q Plot (Quantile–Quantile)** - Plots sample quantiles against theoretical normal quantiles. - Points follow line → normality. --- ``` r qqnorm(resid(fit_mpg2)) qqline(resid(fit_mpg2), col = "red") ``` <!-- --> **2. Shapiro–Wilk Test** - Formal test; sensitive in large samples (often rejects even for trivial deviations). - H₀: normally distributed. --- ``` r shapiro.test(resid(fit_mpg2)) ``` ``` ## ## Shapiro-Wilk normality test ## ## data: resid(fit_mpg2) ## W = 0.92734, p-value = 0.03305 ``` --- **3. Histogram / Density Plot** ``` r ggplot(data.frame(resid = resid(fit_mpg2)), aes(x = resid)) + geom_histogram(aes(y = ..density..), bins = 20, fill = "skyblue", color = "black") + stat_function(fun = dnorm, args = list(mean = mean(resid(fit_mpg2)), sd = sd(resid(fit_mpg2))), color = "red", size = 1) ``` 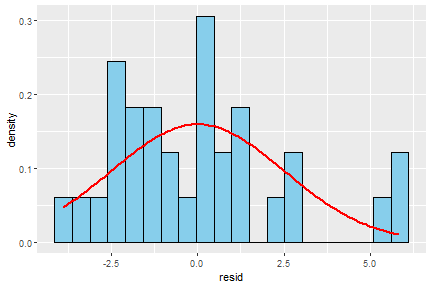<!-- --> --- ### Remedies for Non‑Normality - **Transform the outcome variable** (log, Box–Cox) to make errors more normal. - **Use robust standard errors** (already handle heteroscedasticity, but not non‑normality per se). - **Bootstrapping** for inference (does not assume normality). - **Quantile regression** (if interested in conditional quantiles, not just mean). - In small samples, consider **nonparametric tests**. --- ## Detecting Heteroscedasticity ### 1. Graphical Checks - **Residuals vs. Fitted** (already in your toolkit) Look for a funnel shape: spread increases (or decreases) with fitted values. - **Scale‑Location Plot** (√|standardized residuals| vs. fitted) A rising line suggests heteroscedasticity. --- ``` r # Using a real dataset la_electoral <- read.csv("https://raw.githubusercontent.com/jnseawright/ps405/refs/heads/main/Data/laelectoral.csv") fit <- lm(voteswoninc ~ gdpgrowthlag + votesinclag, data = la_electoral) # Base R scale-location plot (which = 3) plot(fit, which = 3) ``` 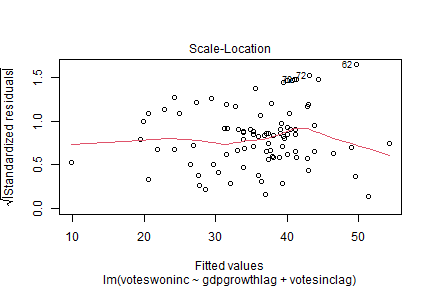<!-- --> --- ### 2. Formal Tests #### Breusch–Pagan / Cook–Weisberg Test - Regress squared residuals on predictors (or fitted values). - H₀: homoscedasticity (all slope coefficients = 0). - If p < 0.05, evidence of heteroscedasticity. --- ``` r library(lmtest) bptest(fit) # studentized version (default) ``` ``` ## ## studentized Breusch-Pagan test ## ## data: fit ## BP = 3.7203, df = 2, p-value = 0.1556 ``` --- #### Goldfeld–Quandt Test - Split data into two groups (e.g., low vs. high X). - Compare error variances between groups. - Useful when heteroscedasticity is related to a specific variable. --- ``` r gqtest(fit, order.by = ~ la_electoral$gdpgrowthlag, fraction = 0.2, alternative = "greater") ``` ``` ## ## Goldfeld-Quandt test ## ## data: fit ## GQ = 1.401, df1 = 33, df2 = 32, p-value = 0.1714 ## alternative hypothesis: variance increases from segment 1 to 2 ``` ``` r # orders by gdpgrowthlag, drops middle 20% of observations ``` --- #### White Test - More general: regress squared residuals on predictors, their squares, and cross‑products. - Detects both heteroscedasticity and nonlinearity. - Implemented via `bptest(fit, ~ fitted(fit) + I(fitted(fit)^2))` or using `whitestrap` package. --- ``` r bptest(fit, ~ poly(fitted(fit), 2)) # using fitted values as proxy ``` --- ## What to Do If Heteroscedasticity Is Present? ### 1. Heteroscedasticity‑Consistent Standard Errors (HCSE) - Also called **robust standard errors** (Huber‑White, sandwich estimator). - Correct standard errors without changing coefficients. - Easy in R: `lmtest::coeftest(fit, vcov = vcovHC(fit))` --- ``` r library(sandwich) library(lmtest) coeftest(fit, vcov = vcovHC(fit, type = "HC1")) # HC1 is common ``` ``` ## ## t test of coefficients: ## ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) -3.37130 11.88188 -0.2837 0.777296 ## gdpgrowthlag 1.04729 0.40885 2.5615 0.012165 * ## votesinclag 0.71660 0.24422 2.9342 0.004286 ** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ``` --- Compare with ordinary SEs: ``` r summary(fit)$coefficients # original ``` ``` ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) -3.3713024 12.0876138 -0.2789055 0.78098690 ## gdpgrowthlag 1.0472868 0.4599732 2.2768432 0.02527799 ## votesinclag 0.7165967 0.2360626 3.0356217 0.00317575 ``` ``` r coeftest(fit, vcov = vcovHC(fit)) # robust ``` ``` ## ## t test of coefficients: ## ## Estimate Std. Error t value Pr(>|t|) ## (Intercept) -3.37130 12.54174 -0.2688 0.788722 ## gdpgrowthlag 1.04729 0.44261 2.3661 0.020221 * ## votesinclag 0.71660 0.25701 2.7882 0.006523 ** ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ``` --- ### 2. Weighted Least Squares (WLS) - If you know the form of heteroscedasticity (e.g., variance proportional to X), you can weight observations. - Estimate weights (often from OLS residuals) then use `lm(..., weights = 1/var_hat)`. --- ``` r # Example: variance proportional to gdpgrowthlag wts <- 1 / fitted(lm(abs(resid(fit)) ~ gdpgrowthlag, data = la_electoral))^2 fit_wls <- lm(voteswoninc ~ gdpgrowthlag + votesinclag, data = la_electoral, weights = wts) ``` --- ### 3. Transform the Outcome Variable - Log, square root, or Box‑Cox transformation can stabilize variance. - Especially useful when variance increases with the mean (common in count or positive‑skewed data). --- ``` r fit_log <- lm(log(voteswoninc) ~ gdpgrowthlag + votesinclag, data = la_electoral) bptest(fit_log) # check if heteroscedasticity reduced ``` --- ### 4. Use Generalised Least Squares (GLS) - Model the error variance explicitly (e.g., `nlme::gls` with `weights = varPower()`). - More flexible but requires specifying variance structure. --- ``` r library(nlme) fit_gls <- gls(voteswoninc ~ gdpgrowthlag + votesinclag, data = la_electoral, weights = varPower(form = ~ fitted(.))) ``` --- ## Summary: Heteroscedasticity - **Detect**: Residual plots, Breusch–Pagan, Goldfeld–Quandt, White test. - **Consequences**: Biased standard errors, invalid inference. - **Remedies**: - Robust standard errors (quick fix, widely accepted) - Weighted Least Squares (if variance structure known) - Transform Y (log, Box‑Cox) - Model variance explicitly (GLS) **Rule of thumb**: Always check for heteroscedasticity in cross‑sectional data. If present, report robust standard errors as a matter of course. --- # Outliers/Influential Cases We have already covered this; diagnostics include: * Cook's Distance * DFBETA --- # `\(R^2\)` and Explained Variance `$$R^2 = 1 - \frac{\sum_{i=1}^{n} e_{i}^2}{\sum_{i=1}^{n} y_{i}^2}$$` --- ### **What `\(R^2\)` Tells Us** - Proportion of variance "explained" - Range: 0 (worst) to 1 (best) --- ### **But in social science...** - **Low `\(R^2\)` is common.** - Political behavior is noisy - Measurement error, multiple causation, heterogeneity --- <table class="table" style="width: auto !important; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:left;"> Study </th> <th style="text-align:right;"> R2 </th> <th style="text-align:left;"> Interpretation </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> Populism and Referenda (Werner and Jacobs 2022) </td> <td style="text-align:right;"> 0.06 </td> <td style="text-align:left;"> A bit low, but okay </td> </tr> <tr> <td style="text-align:left;"> Strongmen and Geographic Vote Choice (Hong et al. 2023) </td> <td style="text-align:right;"> 0.84 </td> <td style="text-align:left;"> Double-check the model </td> </tr> <tr> <td style="text-align:left;"> Explaining Populism (Schafer 2022) </td> <td style="text-align:right;"> 0.17 </td> <td style="text-align:left;"> Normal for individual data </td> </tr> </tbody> </table> --- <table class="table" style="width: auto !important; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:left;"> Study </th> <th style="text-align:right;"> R2 </th> <th style="text-align:left;"> Interpretation </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> Supreme Court Legitimacy (Gibson 2025) </td> <td style="text-align:right;"> 0.24 </td> <td style="text-align:left;"> Good for individual data </td> </tr> <tr> <td style="text-align:left;"> Subnational Democratic Backsliding (Grumbach 2023) </td> <td style="text-align:right;"> 0.68 </td> <td style="text-align:left;"> High numbers because aggregate </td> </tr> </tbody> </table> --- ### **Warning Signs** - `\(R^2\)` > 0.9 in social science: suspect too many variables or close to saturation - `\(R^2\)` changes dramatically with small changes: suspect multicollinearity or missing data issues --- # Practical Workflow ## **The Diagnostic Pipeline** ### **Step 1: Before Modeling** 1. **Theory-driven variable selection** 2. **Check data quality** 3. **Visualize relationships** 4. **Consider transformations** --- ### **Step 2: During Modeling** 1. **Try to start with the most complicated specification you might need and simplify down with tests rather than the other way around** 2. **Examine residuals** 3. **Test for nonlinearities** --- ### **Step 3: After Modeling** 1. **Posterior predictive checks** 2. **Cross-validation** 3. **Sensitivity analysis** 4. **Compare to simpler models** --- ### **Step 4: Reporting** 1. **Transparency about assumptions** 2. **Diagnostic results** 3. **Model limitations** 4. **Robustness checks** ``` ---  ---  ---  --- {width=50%}