class: center, middle, inverse, title-slide .title[ # 3: Matching ] .subtitle[ ## Quantitative Causal Inference ] .author[ ### <large>J. Seawright</large> ] .institute[ ### <small>Northwestern Political Science</small> ] .date[ ### April 17, 2025 ] --- class: center, middle <style type="text/css"> pre { max-height: 400px; overflow-y: auto; } pre[class] { max-height: 200px; } </style> --- ### Matching --- ### The Method of Difference > If an instance in which the phenomenon under investigation occurs, and > an instance in which it does not occur, have every circumstance in > common save one, that one occurring only in the former; the > circumstance in which alone the two instances differ is the effect, or > the cause, or an indispensable part of the cause, of the phenomenon. > (Mill 1843/2002) --- ### The Method of Difference Debunking the Method of Difference --- ### The Potential Outcomes Framework Strictly speaking, for the Method of Difference to work based on a comparison between cases 1 and 2, the condition which must be met is: `$$\begin{aligned} Y_{1,t} = Y_{2,t}\\ Y_{1,c} = Y_{2,c}\end{aligned}$$` --- ### Experiments In a randomized experiment, it is true by the Law of Large Numbers that: `$$\begin{aligned} \frac{\displaystyle\sum_{i: D_{i} = T}Y_{i,t}}{\displaystyle\sum_{i: D_{i} = t} i} \approx \frac{\displaystyle\sum_{j: D_{j} = C}Y_{j,c}}{\displaystyle\sum_{j: D_{j} = c} j}\end{aligned}$$` --- ### Experiments In a randomized experiment, it is true by the Law of Large Numbers that: `$$\begin{aligned} \frac{\displaystyle\sum_{i: D_{i} = T}Y_{i,c}}{\displaystyle\sum_{i: D_{i} = t} i} \approx \frac{\displaystyle\sum_{j: D_{j} = C}Y_{j,c}}{\displaystyle\sum_{j: D_{j} = c} j}\end{aligned}$$` --- ### Matching Suppose, in an observational study, we somehow know that: `$$\begin{aligned} Y_{i, t} = f(\mathbf{X}_{i}) + \epsilon_{i}\\ Y_{i, c} = g(\mathbf{X}_{i}) + \delta_{i}\\ E(\epsilon | \mathbf{X}) = 0\\ E(\delta | \mathbf{X}) = 0\end{aligned}$$` --- ### Matching `$$\begin{aligned} E(Y_{i,t} | D_{i} = T, \mathbf{X}_{i} = \mathbf{W}) = & f(\mathbf{W}) + E(\epsilon_{i})\\ = & f(\mathbf{W}) \\ = & E(Y_{T,i} | D_{i} = C, \\ & \mathbf{X}_{i} = \mathbf{W})\end{aligned}$$` `$$\begin{aligned} E(Y_{C,i} | D_{i} = T, \mathbf{X}_{i} = \mathbf{W}) = \\ E(Y_{C,i} | D_{i} = C, \mathbf{X}_{i} = \mathbf{W})\end{aligned}$$` --- ### Matching Let: `$$\tau_{\mathbf{W}} = E(Y_{T,i} | D_{i} = T, \mathbf{X}_{i} = \mathbf{W}) -\\ E(Y_{C,i} | D_{i} = C, \mathbf{X}_{i} = \mathbf{W})$$` Also let `\(\mathbf{W}\)` have probability density function `\(w()\)`. Then the average treatment effect of `\(D\)` on `\(Y\)` for the population is: `$$ATE = \int \tau_{\mathbf{\omega}} w(\mathbf{\omega})\,d\mathbf{\omega}$$` --- ### Matching as Second-Best Matching is second-best to an experiment because: 1. We need to identify an adequate collection of matching variables, `\(\mathbf{X}\)`. 2. We need stronger modeling assumptions, including assumptions about the existence of and conditional means of `\(\epsilon\)` and `\(\delta\)`. --- ### Matching as Second-Best Matching might be second-best to a fully-specified regression analysis because: 1. We lose the efficiency of using all cases to estimate a small number of parameters. 2. What is the S.E. of `\(\int \tau_{\mathbf{\omega}} w(\mathbf{\omega})\,d\mathbf{\omega}\)`? 3. Does a well-specified regression come closer to replicating experimental findings than something based on matching? --- ### Dehejia and Wahba 1999 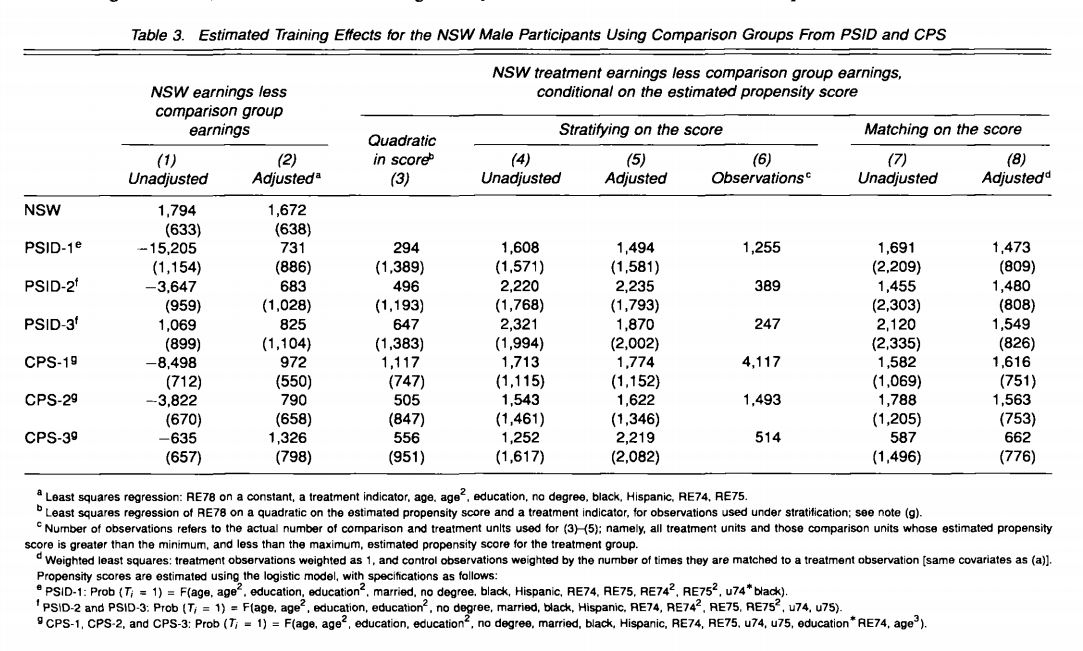 --- ### Smith and Todd 2005 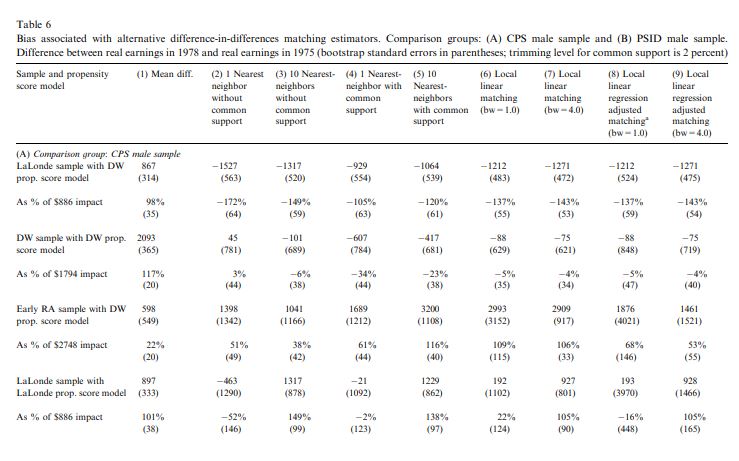 --- ### Arceneaux, Gerber, and Green 2006 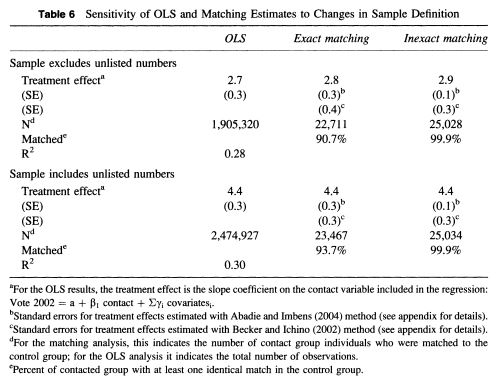 --- ### Glazerman, Levy, and Myers 2003 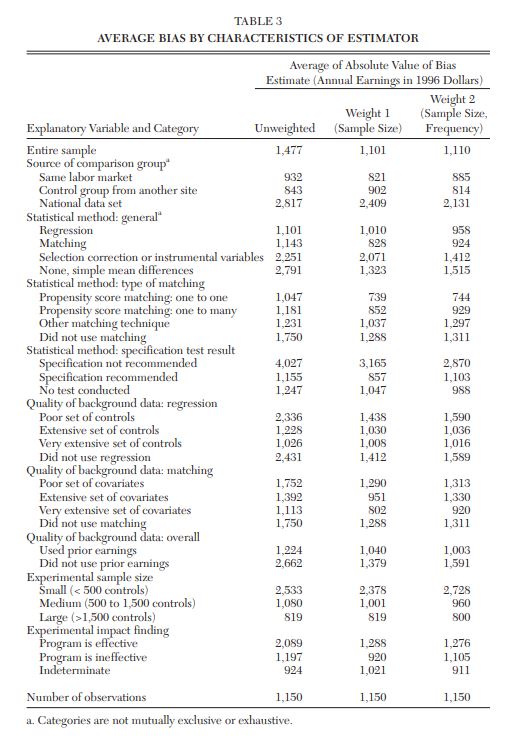 --- ### Shadish, Clark and Steiner 2008  --- ### Cook and Steiner 2010  --- ### So, Why Match? - Experiments aren't always available. - Sometimes, we don't know `\(f()\)` and `\(g()\)`. - Sometimes, we suspect that `\(f()\)` and `\(g()\)` vary across cases. - Matching evens out weights across (at least matched) cases within the sample. --- ### Matching Methods Nearest-neighbor propensity-score matching --- ### Three Causal Quantities 1. ATE: `\(E(Y_{T} - Y_{C})\)` 2. ATT: `\(E(Y_{T} - Y_{C} | D = T)\)` 3. ATC: `\(E(Y_{T} - Y_{C} | D = C)\)` --- ### Pairwise Matching 1. Take a sample of `\(N_{T}\)` treatment cases and `\(N_{C}\)` control cases. 2. For each treatment case, find the control case that "best" matches on `\(\mathbf{X}\)`. Save the difference on `\(Y\)` between those two cases 3. Average the resulting paired differences. Use this as an estimate of ATT. --- ### Propensity Score The *propensity score* for case `\(i\)` is the probability that `\(D_{i} = T\)` conditional on `\(\mathbf{X}_{i}\)`. A well-estimated propensity score contains all the information about `\(\mathbf{X}_{i}\)` that is relevant to causal inference. --- ### Application: Female Legislators - It is widely believed that proportional representation electoral rules produce more female legislators than do single-member district rules (e.g., Kenworthy and Malami 1999, Matland 1998, Norris 2004, Paxton and Kunovich 2003, Reynolds 1999, Rule 1987, Siaroff 2000). - Several regression analyses have found effects in the neighborhood of 7-12%. --- ### Application: Female Legislators - These models have assumed that there is a single, constant effect of electoral rules on women's legislative inclusion. Is that assumption plausible? - For example, is the ATT equal to the ATC? --- ### Application: Female Legislators  --- ### Application: Female Legislators --- ``` r fourelec <- read.csv("https://github.com/jnseawright/PS406/raw/main/data/fourelec.csv") fourelectrim <- na.omit(data.frame( country=fourelec$country, maj=fourelec$maj,prop65=fourelec$prop65, lyp=fourelec$lyp,gastil=fourelec$gastil, col_uka=fourelec$col_uka, laam=fourelec$laam, federal=fourelec$federal, wom_1st=fourelec$wom_1st, quota=fourelec$Quota)) fourelectrim <- fourelectrim %>% filter(quota==0) ``` --- ``` r pscore <- glm(maj ~ prop65 + I(log(lyp)) + gastil + federal + col_uka + laam, family=binomial(link=logit), data=fourelectrim)$fitted ``` --- ``` r library(Matching) ``` ``` ## Warning: package 'Matching' was built under R version 4.4.3 ``` ``` ## Loading required package: MASS ``` ``` ## ## Attaching package: 'MASS' ``` ``` ## The following object is masked from 'package:dplyr': ## ## select ``` ``` ## ## ## ## Matching (Version 4.10-15, Build Date: 2024-10-14) ## ## See https://www.jsekhon.com for additional documentation. ## ## Please cite software as: ## ## Jasjeet S. Sekhon. 2011. ``Multivariate and Propensity Score Matching ## ## Software with Automated Balance Optimization: The Matching package for R.'' ## ## Journal of Statistical Software, 42(7): 1-52. ## ## ``` --- ``` r firstmatch <- with(fourelectrim,Match( Y=wom_1st,Tr=maj,X=pscore,est="ATT")) summary(firstmatch) ``` ``` ## ## Estimate... 4.1167 ## AI SE...... 3.8121 ## T-stat..... 1.0799 ## p.val...... 0.28019 ## ## Original number of observations.............. 59 ## Original number of treated obs............... 24 ## Matched number of observations............... 24 ## Matched number of observations (unweighted). 25 ``` --- ``` r secondmatch <- with(fourelectrim,Match( Y=wom_1st,Tr=maj,X=pscore,est="ATC")) summary(secondmatch) ``` ``` ## ## Estimate... -6.9143 ## AI SE...... 4.5323 ## T-stat..... -1.5256 ## p.val...... 0.12712 ## ## Original number of observations.............. 59 ## Original number of control obs............... 35 ## Matched number of observations............... 35 ## Matched number of observations (unweighted). 35 ``` --- ### What are the actual matches? ``` r firstmatched.data <- data.frame(treated.country = fourelectrim$country[firstmatch$index.treated], control.country = fourelectrim$country[firstmatch$index.control], treated.wom_1st = fourelectrim$wom_1st[firstmatch$index.treated], control.wom_1st = fourelectrim$wom_1st[firstmatch$index.control], treated.pscore = pscore[firstmatch$index.treated], control.pscore = pscore[firstmatch$index.control]) ``` --- ``` r firstmatched.data ``` ``` ## treated.country control.country treated.wom_1st control.wom_1st ## 1 Australia Fiji 25.3 8.5 ## 2 Bahamas Fiji 20.0 8.5 ## 3 Barbados Fiji 10.7 8.5 ## 4 Belize Fiji 3.4 8.5 ## 5 Botswana Fiji 17.0 8.5 ## 6 Canada Malta 20.6 9.2 ## 7 Chile Colombia 12.5 12.1 ## 8 Gambia Fiji 13.2 8.5 ## 9 Ghana Fiji 9.0 8.5 ## 10 India Fiji 8.8 8.5 ## 11 Jamaica Fiji 11.7 8.5 ## 12 Japan Czech Republic 7.3 17.0 ## 13 Malawi Fiji 9.3 8.5 ## 14 Malaysia Fiji 10.4 8.5 ## 15 Mauritius Fiji 5.7 8.5 ## 16 New Zeland Ireland 28.3 13.3 ## 17 Papua N. Guin Fiji 0.9 8.5 ## 18 Singapore Malta 16.0 9.2 ## 19 St. Vincent&G Fiji 22.7 8.5 ## 20 Thailand Turkey 9.2 4.4 ## 21 Uganda Fiji 23.9 8.5 ## 22 Uk Bulgaria 17.9 26.2 ## 23 Uk Italy 17.9 9.8 ## 24 Zambia Fiji 12.7 8.5 ## 25 Zimbabwe Fiji 10.0 8.5 ## treated.pscore control.pscore ## 1 0.78335949 0.77301728 ## 2 0.90234710 0.77301728 ## 3 0.75284234 0.77301728 ## 4 0.90715679 0.77301728 ## 5 0.83000744 0.77301728 ## 6 0.69284547 0.62133392 ## 7 0.25268192 0.26557547 ## 8 0.71773648 0.77301728 ## 9 0.71897144 0.77301728 ## 10 0.91670414 0.77301728 ## 11 0.81193784 0.77301728 ## 12 0.06040609 0.06110017 ## 13 0.73849743 0.77301728 ## 14 0.93004796 0.77301728 ## 15 0.76661901 0.77301728 ## 16 0.40698231 0.46211707 ## 17 0.81890488 0.77301728 ## 18 0.67822586 0.62133392 ## 19 0.92829937 0.77301728 ## 20 0.15154323 0.13895447 ## 21 0.72214510 0.77301728 ## 22 0.04540721 0.04652898 ## 23 0.04540721 0.04426235 ## 24 0.76151005 0.77301728 ## 25 0.76775725 0.77301728 ``` --- ``` r library(optmatch) ``` ``` ## Warning: package 'optmatch' was built under R version 4.4.3 ``` --- ``` r elecrulespscore <- glm(maj ~ prop65 + I(log(lyp)) + gastil + federal + col_uka + laam, family=binomial(link=logit), data=fourelectrim) elecrules.pairmatch <- pairmatch(elecrulespscore, data=fourelectrim) summary(elecrules.pairmatch) ``` ``` ## Structure of matched sets: ## 1:1 0:1 ## 24 11 ## Effective Sample Size: 24 ## (equivalent number of matched pairs). ``` ``` r anova(lm(fourelectrim$wom_1st ~ elecrules.pairmatch + fourelectrim$maj)) ``` ``` ## Analysis of Variance Table ## ## Response: fourelectrim$wom_1st ## Df Sum Sq Mean Sq F value Pr(>F) ## elecrules.pairmatch 23 1697.07 73.786 0.9635 0.5351 ## fourelectrim$maj 1 205.01 205.013 2.6771 0.1154 ## Residuals 23 1761.36 76.581 ``` --- ### Variants of Matching - Full matching - Caliper matching - Coarsened exact matching --- ``` r elecrules.fullmatch <- fullmatch(maj ~ prop65 + I(log(lyp)) + gastil + federal + col_uka + laam, data=fourelectrim) summary(elecrules.fullmatch) ``` ``` ## Structure of matched sets: ## 1:1 1:5+ ## 22 2 ## Effective Sample Size: 25.5 ## (equivalent number of matched pairs). ``` ``` r anova(lm(fourelectrim$wom_1st ~ elecrules.fullmatch + fourelectrim$maj)) ``` ``` ## Analysis of Variance Table ## ## Response: fourelectrim$wom_1st ## Df Sum Sq Mean Sq F value Pr(>F) ## elecrules.fullmatch 23 2718.1 118.18 1.2564 0.2673 ## fourelectrim$maj 1 143.3 143.26 1.5231 0.2256 ## Residuals 34 3198.0 94.06 ``` --- ``` r elecrules.distmat <- match_on(maj ~ prop65 + I(log(lyp)) + gastil + federal + col_uka + laam, data=fourelectrim) + caliper(match_on(elecrulespscore), width = 3) (elecrules.caliperfull <- fullmatch(elecrules.distmat, data=fourelectrim)) ``` ``` ## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ## 1.1 1.6 1.2 1.3 1.4 1.5 1.22 1.6 1.7 1.7 1.15 1.22 1.12 1.19 1.22 1.14 ## 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 ## 1.12 1.8 1.1 1.9 1.22 1.2 1.22 1.12 1.10 1.16 1.3 1.22 1.11 1.12 1.22 1.12 ## 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 ## 1.13 1.14 1.4 1.15 1.5 1.12 1.16 1.10 1.22 1.17 1.8 1.22 1.13 1.23 1.14 1.12 ## 49 50 51 52 53 54 55 56 57 58 59 ## 1.17 1.9 1.19 1.22 1.20 1.20 1.9 1.22 1.11 1.23 1.9 ``` ``` r summary(elecrules.caliperfull) ``` ``` ## Structure of matched sets: ## 3:1 2:1 1:1 1:5+ ## 1 1 17 2 ## Effective Sample Size: 23.4 ## (equivalent number of matched pairs). ``` --- ``` r anova(lm(fourelectrim$wom_1st ~ elecrules.caliperfull + fourelectrim$maj)) ``` ``` ## Analysis of Variance Table ## ## Response: fourelectrim$wom_1st ## Df Sum Sq Mean Sq F value Pr(>F) ## elecrules.caliperfull 20 2410.7 120.537 1.2606 0.2643 ## fourelectrim$maj 1 110.8 110.820 1.1590 0.2886 ## Residuals 37 3537.8 95.616 ``` --- ``` r library(cem) ``` ``` ## Warning: package 'cem' was built under R version 4.4.3 ``` ``` ## Loading required package: tcltk ``` ``` ## Loading required package: lattice ``` ``` ## ## How to use CEM? Type vignette("cem") ``` ``` ## ## Attaching package: 'cem' ``` ``` ## The following object is masked from 'package:optmatch': ## ## pair ``` --- ``` r elecrules.cem <- cem(treatment="maj", data=fourelectrim, drop="wom_1st") ``` ``` ## Warning in reduce.var(data[[i]], cutpoints[[vnames[i]]]): NAs introduced by ## coercion ``` ``` ## ## Using 'maj'='1' as baseline group ``` ``` r elecrules.att <- att(elecrules.cem, wom_1st ~ maj, data=fourelectrim) ``` --- ``` r summary(elecrules.att) ``` ``` ## ## Treatment effect estimation for data: ## ## G0 G1 ## All 35 24 ## Matched 8 3 ## Unmatched 27 21 ## ## Linear regression model estimated on matched data only ## ## Coefficients: ## Estimate Std. Error t value p-value ## (Intercept) 25.2861 4.6080 5.4874 0.0003864 *** ## maj -7.4528 8.8236 -0.8446 0.4201979 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ``` --- ### Balance - Recall that matching only helps for causal inference if the distribution of `\(\mathbf{X}\)` in the treatment group is essentially the same as the distribution of `\(\mathbf{X}\)` in the control group. - A necessary (but not sufficient) condition for successful causal inference from matching is that the mean of each variable in `\(\mathbf{X}\)` be essentially the same in the matched treatment and control groups. --- ``` r firstmatch.mb <- MatchBalance(maj~prop65 + I(log(lyp)) + gastil + federal + col_uka + laam, data=fourelectrim, match.out=firstmatch, nboots=500) ``` ``` ## ## ***** (V1) prop65 ***** ## Before Matching After Matching ## mean treatment........ 6.2326 6.2326 ## mean control.......... 10.599 5.6009 ## std mean diff......... -104.33 15.093 ## ## mean raw eQQ diff..... 4.2148 1.3848 ## med raw eQQ diff..... 3.4351 1.0169 ## max raw eQQ diff..... 7.3052 6.0434 ## ## mean eCDF diff........ 0.24762 0.14625 ## med eCDF diff........ 0.27143 0.12 ## max eCDF diff........ 0.46429 0.36 ## ## var ratio (Tr/Co)..... 0.83882 1.3321 ## T-test p-value........ 0.00038984 0.25273 ## KS Bootstrap p-value.. 0.006 0.032 ## KS Naive p-value...... 0.0026349 0.047003 ## KS Statistic.......... 0.46429 0.36 ## ## ## ***** (V2) I(log(lyp)) ***** ## Before Matching After Matching ## mean treatment........ 2.0947 2.0947 ## mean control.......... 2.1487 2.1317 ## std mean diff......... -36.838 -25.246 ## ## mean raw eQQ diff..... 0.04995 0.10459 ## med raw eQQ diff..... 0.031318 0.066677 ## max raw eQQ diff..... 0.13673 0.26585 ## ## mean eCDF diff........ 0.092776 0.23375 ## med eCDF diff........ 0.066667 0.24 ## max eCDF diff........ 0.27619 0.44 ## ## var ratio (Tr/Co)..... 2.2316 15.733 ## T-test p-value........ 0.123 0.18286 ## KS Bootstrap p-value.. 0.148 0.004 ## KS Naive p-value...... 0.18069 0.0055155 ## KS Statistic.......... 0.27619 0.44 ## ## ## ***** (V3) gastil ***** ## Before Matching After Matching ## mean treatment........ 2.6852 2.6852 ## mean control.......... 2.1853 3.3102 ## std mean diff......... 34.352 -42.951 ## ## mean raw eQQ diff..... 0.53762 1.0044 ## med raw eQQ diff..... 0.47222 0.83333 ## max raw eQQ diff..... 1.3333 2.3333 ## ## mean eCDF diff........ 0.11601 0.224 ## med eCDF diff........ 0.10357 0.24 ## max eCDF diff........ 0.2631 0.44 ## ## var ratio (Tr/Co)..... 1.6859 1.9046 ## T-test p-value........ 0.1635 0.058258 ## KS Bootstrap p-value.. 0.188 0.004 ## KS Naive p-value...... 0.1935 0.0081118 ## KS Statistic.......... 0.2631 0.44 ## ## ## ***** (V4) federal ***** ## Before Matching After Matching ## mean treatment........ 0.16667 0.16667 ## mean control.......... 0.085714 0 ## std mean diff......... 21.264 43.78 ## ## mean raw eQQ diff..... 0.083333 0.16 ## med raw eQQ diff..... 0 0 ## max raw eQQ diff..... 1 1 ## ## mean eCDF diff........ 0.040476 0.08 ## med eCDF diff........ 0.040476 0.08 ## max eCDF diff........ 0.080952 0.16 ## ## var ratio (Tr/Co)..... 1.7965 Inf ## T-test p-value........ 0.38079 0.038854 ## ## ## ***** (V5) col_uka ***** ## Before Matching After Matching ## mean treatment........ 0.68767 0.68767 ## mean control.......... 0.16571 0.7265 ## std mean diff......... 157.25 -11.7 ## ## mean raw eQQ diff..... 0.527 0.04944 ## med raw eQQ diff..... 0.712 0.024 ## max raw eQQ diff..... 0.876 0.252 ## ## mean eCDF diff........ 0.37641 0.17111 ## med eCDF diff........ 0.47024 0.12 ## max eCDF diff........ 0.63333 0.48 ## ## var ratio (Tr/Co)..... 1.067 0.98596 ## T-test p-value........ 2.33e-07 0.057417 ## KS Bootstrap p-value.. < 2.22e-16 0.002 ## KS Naive p-value...... 3.223e-06 0.002344 ## KS Statistic.......... 0.63333 0.48 ## ## ## ***** (V6) laam ***** ## Before Matching After Matching ## mean treatment........ 0.25 0.25 ## mean control.......... 0.14286 0.041667 ## std mean diff......... 24.223 47.1 ## ## mean raw eQQ diff..... 0.125 0.2 ## med raw eQQ diff..... 0 0 ## max raw eQQ diff..... 1 1 ## ## mean eCDF diff........ 0.053571 0.1 ## med eCDF diff........ 0.053571 0.1 ## max eCDF diff........ 0.10714 0.2 ## ## var ratio (Tr/Co)..... 1.5522 4.6957 ## T-test p-value........ 0.32865 0.019423 ## ## ## Before Matching Minimum p.value: < 2.22e-16 ## Variable Name(s): col_uka Number(s): 5 ## ## After Matching Minimum p.value: 0.002 ## Variable Name(s): col_uka Number(s): 5 ``` --- ``` r library(cobalt) ``` ``` ## Warning: package 'cobalt' was built under R version 4.4.3 ``` ``` ## cobalt (Version 4.5.5, Build Date: 2024-04-02) ``` ``` r bal.tab(elecrules.fullmatch, maj ~ prop65 + I(log(lyp)) + gastil + federal + col_uka + laam, data=fourelectrim, thresholds = c(m = .2, v = 2)) ``` ``` ## Balance Measures ## Type Diff.Adj M.Threshold V.Ratio.Adj V.Threshold ## prop65 Contin. -0.6664 Not Balanced, >0.2 0.8512 Balanced, <2 ## I(log(lyp)) Contin. -0.1539 Balanced, <0.2 2.2989 Not Balanced, >2 ## gastil Contin. 0.1069 Balanced, <0.2 1.6055 Balanced, <2 ## federal Binary 0.0417 Balanced, <0.2 . ## col_uka Contin. 1.3437 Not Balanced, >0.2 0.8279 Balanced, <2 ## laam Binary 0.0417 Balanced, <0.2 . ## ## Balance tally for mean differences ## count ## Balanced, <0.2 4 ## Not Balanced, >0.2 2 ## ## Variable with the greatest mean difference ## Variable Diff.Adj M.Threshold ## col_uka 1.3437 Not Balanced, >0.2 ## ## Balance tally for variance ratios ## count ## Balanced, <2 3 ## Not Balanced, >2 1 ## ## Variable with the greatest variance ratio ## Variable V.Ratio.Adj V.Threshold ## I(log(lyp)) 2.2989 Not Balanced, >2 ## ## Sample sizes ## Control Treated ## All 35. 24 ## Matched (ESS) 25.82 24 ## Matched (Unweighted) 35. 24 ``` --- ### Sensitivity Analysis - Even net of `\(\mathbf{X}\)`, it could be the case that some other variable causes cases to have differential probabilities of treatment. - Let `\(\gamma\)` be the odds ratio for the probability that matched cases will be assigned to the treatment, conditional on their values of the unobserved variable: `$$\gamma = \frac{P(D_{i} = t | \mathbf{X}_{i}, u_{i})}{P(D_{i} = t | \mathbf{X}_{i}, u_{j})}$$` --- ### Sensitivity Analysis - How does the range of possible `\(P\)` values on our ATE estimate depend on the value of `\(\gamma\)`? --- ``` r library(rbounds) psens(fourelectrim$wom_1st[firstmatch$index.treated], fourelectrim$wom_1st[firstmatch$index.control], Gamma=2, GammaInc=.1) ``` ``` ## ## Rosenbaum Sensitivity Test for Wilcoxon Signed Rank P-Value ## ## Unconfounded estimate .... 0.0074 ## ## Gamma Lower bound Upper bound ## 1.0 0.0074 0.0074 ## 1.1 0.0041 0.0129 ## 1.2 0.0022 0.0204 ## 1.3 0.0012 0.0300 ## 1.4 0.0007 0.0418 ## 1.5 0.0004 0.0556 ## 1.6 0.0002 0.0714 ## 1.7 0.0001 0.0889 ## 1.8 0.0001 0.1080 ## 1.9 0.0000 0.1284 ## 2.0 0.0000 0.1499 ## ## Note: Gamma is Odds of Differential Assignment To ## Treatment Due to Unobserved Factors ## ``` --- <img src="images/Ruggeri1.png" width="90%" /> --- <img src="images/Ruggeri2.png" width="50%" /> --- <img src="images/Ruggeri3.png" width="60%" /> --- <img src="images/Ruggeri4.png" width="70%" />